一、本模組的方法學定位
| 面向 | 模組一(京都櫻花) | 模組二(勃艮第葡萄) |
|---|---|---|
| 統計結構 | 漸進式趨勢(gradient) | 結構性斷層(breakpoint) |
| 核心方法 | OLS 迴歸、相關係數 | t 檢定、CUSUM 掃描 |
| 視覺隱喻 | 剪刀效應(scissors) | 歷史斷層(the cliff) |
| 時間跨度 | 1,200 年 | 634 年 |
| 文化符碼 | 和歌、花見、季語 | 風土、釀酒學、飲食遺產 |
兩個模組在設計上刻意互補:若模組一讓學生感受「連續的緩慢錯亂」,模組二則讓學生面對「某一年之後一切都不一樣了」的結構性斷裂。兩者並列,方能建立對氣候信號多樣形式的辨識能力。
二、課堂前置準備
2.1 環境
與模組一相同。Colab 首次執行:
!apt-get install -y fonts-noto-cjk -q2.2 資料來源說明
- 主要資料:Chuine et al. (2004) 刊於 Nature 的勃艮第葡萄採收日重建,範圍 1370–2003。NOAA 古氣候資料庫永久歸檔。
- 延伸參照:Labbé et al. (2019) 刊於 Climate of the Past 之 Beaune 1354–2018 同質化序列。此資料主要在 Euro-Climhist(unibe.ch)平台提供互動查詢,不便於直接程式取用,因此本模組以 Chuine 2004 為計算底本,並在教學解說中引用 Labbé 2019 的關鍵統計。
2.3 背景閱讀(課前建議發給學生)
- EGU 新聞稿:〈Burgundy wine grapes tell climate story〉(2019/08/29)
- Thomas Labbé 在《The Dantean Anomaly》部落格的通俗說明(2019/09/11)
- 國家地理中文版有中譯介紹此研究
三、課堂節奏建議(90 分鐘版)
| 時段 | 內容 | 教學重點 | 對應程式 |
|---|---|---|---|
| 0–10 分 | 場景設定 | 簡述勃艮第葡萄園的 UNESCO 世界遺產地位;一段關於「風土」的葡萄酒評論朗讀 | — |
| 10–20 分 | 連結模組一 | 回顧剪刀效應;提問:「會不會有另一種氣候信號,不是漸進而是一夜之間的?」 | — |
| 20–35 分 | 檔案即資料 | 播放 Labbé 教授訪談片段,讓學生看見 15 世紀葡萄工人薪資帳本的照片。強調「資料來自檔案,檔案來自人」 | 第 1 節 |
| 35–55 分 | 執行程式、觀察結果 | 由教師示範 main(),特別注意 Cohen's d 與 CUSUM 的自動結果 | 第 3、4 節 |
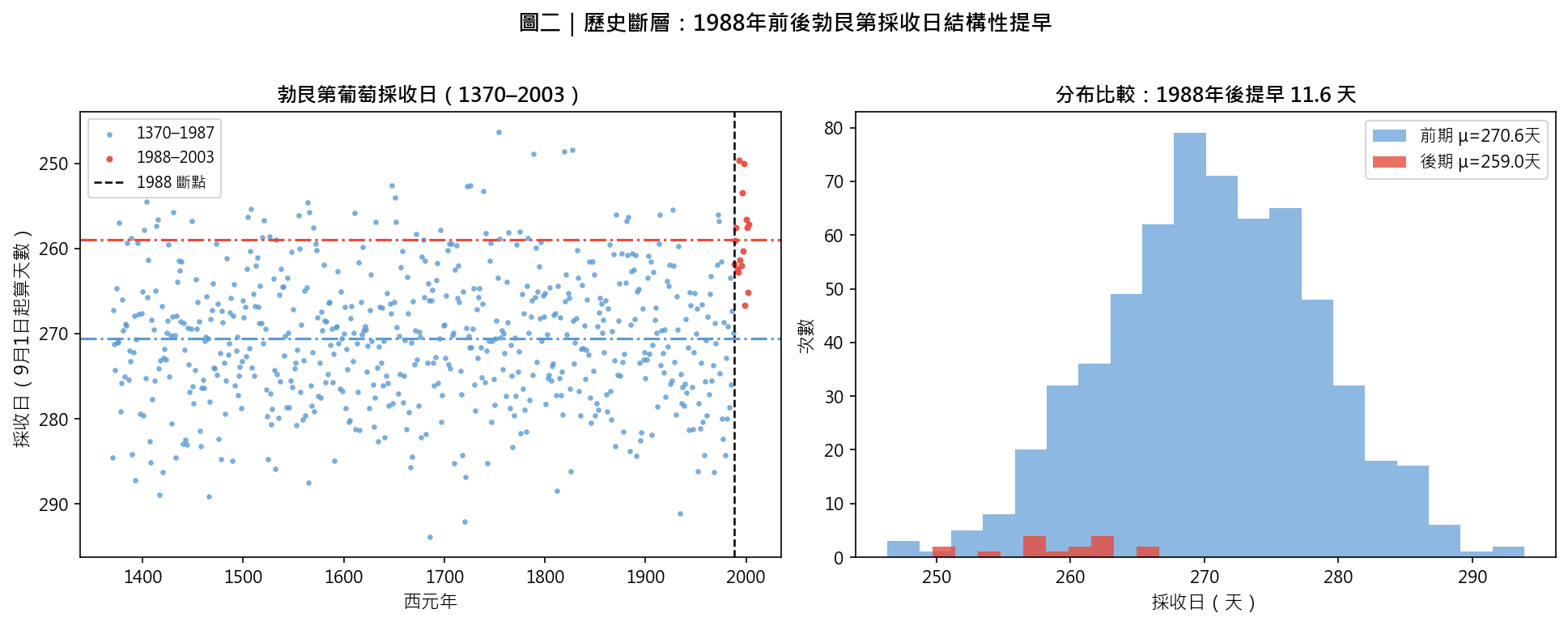
| 55–70 分 | 解讀三張圖 | 全景斷層圖(圖 2a)→ 分布比較(圖 2b)→ 雙軸時序(圖 2c)。三張圖三種說故事方式 | 第 7、8、9 節 |
| 70–85 分 | 分組討論 | 選一題(見程式第 11 節)深入討論,特別推薦討論題三(1540 年資料錯誤) | 第 11 節 |
| 85–90 分 | 收尾 | 連結下一模組(預告):「如果葡萄與櫻花都在說話,那麼我們自己的身體呢?」 | → 模組三 |
四、關鍵統計概念之淺白解釋
4.1 什麼是「結構突變」(structural break)?
- 直覺比喻:想像你在爬一個平緩的斜坡,突然走到一個懸崖上,下面是另一個新的平台。這個「崖邊」就是結構突變點。
- 與「趨勢」的差別:趨勢是整路都在上坡(或下坡);結構突變是某一天「規則」變了。
- 教學案例:新冠疫情前後的航空客運量、金融危機前後的房價、1987 年台灣解嚴前後的言論自由度——都是結構突變而非漸進趨勢。
4.2 什麼是 Cohen's d?
- 定義:兩組均值差距,除以「共同標準差」,得到「幾個標準差」的差距。
- 經驗指標:
- d < 0.2:微小
- 0.2 ≤ d < 0.5:小
- 0.5 ≤ d < 0.8:中
- d ≥ 0.8:大
- 為什麼重要:p 值只告訴你「有沒有差距」,Cohen's d 告訴你「差距有多大」。本模組通常會得到 d > 0.8 的大效應量,這比單看 p < .001 更有說服力。
4.3 什麼是 CUSUM 掃描?
- 直覺:讓程式「不預設任何假設」,逐年測試「如果在這一年切開,前後兩段會不會特別均勻?」最後選出切得最均勻的那一年。
- 教學重點:如果 CUSUM 找到的斷點與 Labbé 論文宣稱的 1988 相近,代表「資料自己在說話」;反之則需要追問為什麼。
- 統計倫理:先驗假設(t 檢定)與事後搜尋(CUSUM)之間的界線,正是當代統計學關於「p-hacking」爭議的核心。
五、教學關鍵時刻:1540 年的故事
這個故事非常適合作為整堂課的高潮,強烈建議教師預留 10 分鐘深入講述。
1540 年,歐洲經歷了一場「千年大旱(Drought of 1540)」。根據 Wetter & Pfister (2013) 在 Climatic Change 期刊的研究,該年的春夏氣溫可能比任何 20 世紀的極端熱年還高。這應當在葡萄採收日上留下戲劇性的痕跡。
然而:
- Chuine et al. (2004) 的 Nature 論文記載 1540 年的採收日為 10 月 4 日(DOY 278)——完全不像極端熱年
- Labbé & Gaveau (2011) 回到第戎市議會原始檔案重查,發現真正的採收日為 9 月 3 日(DOY 247)——差距整整 31 天
為什麼會有這麼大的錯誤?因為 Chuine 等人使用的是 19 世紀 Angot(1885)的二手編纂資料,而 Angot 當年可能抄錯了字。這個錯誤在 Nature 發表後流傳了 15 年,才被願意回到原始檔案的歷史學家糾正。
教學啟發
- 「公開資料」不等於「正確資料」
- 「同儕審查過的論文」不等於「沒有錯誤的論文」
- 科學資料的修正需要跨領域合作:氣候學家需要歷史學家,歷史學家需要統計學家
- 這正是 Van Audenhove(2021)所稱「批判資料素養」的核心——資料永遠需要被質疑
六、常見學生提問與建議回應
為什麼斷點是 1988 年?全球暖化不是早就開始了嗎?
全球暖化的「信號」在 20 世紀上半葉已開始,但從「全球年均溫異常值」來看,持續高於 1951–1980 基期的連續記錄大約從 1977 年開始,而「顯著偏離任何歷史先例」的階段確實可定位到 1980 年代末。不同氣候變數的斷點時間不同:北極海冰下降的斷點約在 1979–1985;歐洲春夏溫度在 1987–1988;北大西洋海洋熱含量約在 1990 年代初。1988 是一個「多訊號匯聚」的年份。
葡萄酒真的會因此變難喝嗎?
釀酒學家的看法:短期看,勃艮第葡萄在 1990s–2010s 確實釀出了許多「偉大年份」;但長期看,過熱的夏季會導致(1)葡萄糖分過高 → 酒精度過高(>15%)、(2)酸度不足 → 酒體缺乏骨架、(3)成熟曲線錯亂 → 糖分成熟時酚類未成熟。業界對策:種植更高海拔(爬山坡)、改種耐熱品種(但這違反 AOC 法規)、或移往英國(英國已出現氣泡酒產業)。
為什麼只用葡萄一種作物?用小麥、稻米會不會更代表性?
葡萄的優勢是(1)採收日受官方規範,留下完整文書紀錄;(2)對春夏氣溫極度敏感;(3)單一品種(黑皮諾)種植年代久、變化小。小麥與稻米的採收決策受品種、灌溉、肥料多重影響,難以單純歸因於氣候。
台灣有沒有類似的資料?
台灣尚無單一作物長達六百年的連續採收日紀錄。但相似的長期物候資料包括:台灣銀合歡花期(林務局監測)、玉山森林界線變化(玉山國家公園)、台灣山櫻花期(氣象署)。建議學生進一步探索氣象署「農業氣象觀測網」。
七、評量建議
7.1 形成性評量(課中)
請學生在圖 2a 上標註:(a)兩個「前段平均以下」的極端早採年份;(b)一段長達 50 年以上的「低溫時期」(採收日普遍偏晚)。並對照歷史事件(小冰期、火山爆發等)解釋。
7.2 總結性評量(課後)
選一題繳交 800–1,000 字短文:
- 統計素養題:在
breakpoint_ttest()函式中,將break_year參數分別設為 1900、1950、1988,比較三者的 t 值、p 值、Cohen's d。若你是審稿人,為什麼會認為 1988 是最合理的斷點?(提示:Cohen's d 的大小是關鍵。) - 資料批判題:查閱 Labbé & Gaveau (2011) 與 Wetter & Pfister (2013) 兩篇論文關於 1540 年的討論,撰寫一段敘述說明「資料錯誤如何影響科學結論」。
- 跨模組整合題:結合模組一與模組二的結果,製作一份簡報式的投影片(3 張)向非科學背景的朋友解釋:「為什麼氣候變遷不是『最近才開始』,而是『最近才加速』?」
八、延伸閱讀
- Chuine, I., Yiou, P., Viovy, N., Seguin, B., Daux, V., & Le Roy Ladurie, E. (2004). Grape ripening as a past climate indicator. Nature, 432, 289–290.
- Labbé, T., Pfister, C., Brönnimann, S., Rousseau, D., Franke, J., & Bois, B. (2019). The longest homogeneous series of grape harvest dates, Beaune 1354–2018. Climate of the Past, 15, 1485–1501.
- Labbé, T., & Gaveau, F. (2011). Les dates de bans de vendange à Dijon : établissement critique et révision archivistique d'une série ancienne. Revue Historique, 657, 19–51.
- Wetter, O., & Pfister, C. (2013). An underestimated record breaking event: Why summer 1540 was likely warmer than 2003. Climate of the Past, 9, 41–56.
- Van Audenhove, L., Van den Broeck, W., & Mariën, I. (2020). Data literacy and education: Introduction and the challenges for our field. Journal of Media Literacy Education, 12(3), 1–5.
教學者自我提醒:模組二的核心是讓學生學會「辨識斷層」——在資料中、在文化中、在歷史中、在未來的自己身上。 氣候變遷作為一個超物件,它不會一直是漸進的,有時它會以一次地質斷層的方式突然顯現。 而當那一刻來臨,我們需要能在圖上認出它。