一、本模組的教學定位
| 面向 | 模組一(京都櫻花) | 模組二(勃艮第葡萄) | 模組三(台灣登革熱) |
|---|---|---|---|
| 統計結構 | 漸進趨勢 | 結構斷層 | 非線性閾值(倒 U) |
| 核心方法 | OLS、相關係數 | t 檢定、CUSUM | OLS vs GAM、相關係數的盲點 |
| 視覺隱喻 | 剪刀效應 | 歷史斷層 | 看不見的駝峰 |
| 情意定位 | 浪漫入口 | 文化憂鬱 | 文化憂鬱 → 物理衝擊的橋接 |
一句話定位:這是全課程唯一的「統計方法論」模組。它教學生的不是「氣候很可怕」, 而是「不要相信你沒有檢查過形狀的相關係數」。前兩個模組用圖打動人心, 唯獨這一個模組,要學生對圖、對統計量保持戒心——尤其對那些「只報告一個相關係數、卻從不給你看散點圖」的論文與新聞。
二、課堂前置準備
2.1 環境
與前兩模組相同。Colab 首次執行:
!apt-get install -y fonts-noto-cjk -q # 中文字型(裝完需 Runtime → Restart)
!pip install pygam -q # 選用;不裝也能跑(自動回退 statsmodels)本模組刻意設計成「有 pygam 就用 pygam,沒有就用 statsmodels 的 GLMGam + B-spline」, 兩者結果在教學上等價。這本身就是一個教學點:同一個統計概念(平滑樣條),可以有很多種實作工具。
2.2 資料來源說明
- 登革熱:衛福部疾病管制署「登革熱每日確定病例」開放資料(
Dengue_Daily.csv,約 18 MB,1998 迄今逐案)。本模組篩選本土病例 × 居住台南市,依「發病日」聚合為月病例數。授權為政府資料開放授權條款第 1 版。 - 氣溫:NASA POWER 的 T2M(地表 2 公尺月均溫),台南座標 (22.99°N, 120.21°E),無需金鑰,底層為 MERRA-2 再分析資料。
- 合併:兩個異質資料源以「年-月」為鍵值合併(2008–2023,共 192 個月)。這個合併動作本身,就是資料識讀「使用資料(Using data)」能力域的核心練習。
2.3 為什麼用台南?
- 台南是 2015 年台灣登革熱大爆發的震央:當年單一縣市本土病例超過 2.2 萬例,本資料中單月最高出現在 2015 年 9 月,達 12,814 例。
- 選用單一縣市的本土序列,能讓「氣溫—傳播」訊號不被跨縣市異質性稀釋,也讓台灣學生對「自己島上、不久前才發生」的疫情產生切身感。
- 進階學生可改
COUNTY變數,比較高雄、屏東,或改成全台彙整,觀察形狀如何變化。
三、課堂節奏建議(90 分鐘版)
| 時段 | 內容 | 教學重點 | 對應程式 |
|---|---|---|---|
| 0–10 分 | 場景設定 | 播放 2015 台南登革熱新聞片段;提問「氣溫越高,登革熱就越嚴重,對嗎?」先讓學生投票 | — |
| 10–20 分 | 連結前模組 | 回顧模組一(漸進)、模組二(斷層):「我們看過兩種形狀了。今天這一種,會騙過你的直覺,也會騙過電腦」 | — |
| 20–35 分 | 資料合併實作 | 學生親自執行 build_dataset(),觀察疾管署 18 MB 資料下載、本土篩選、與 NASA 氣溫的年-月合併 | 第 1、2 節 |
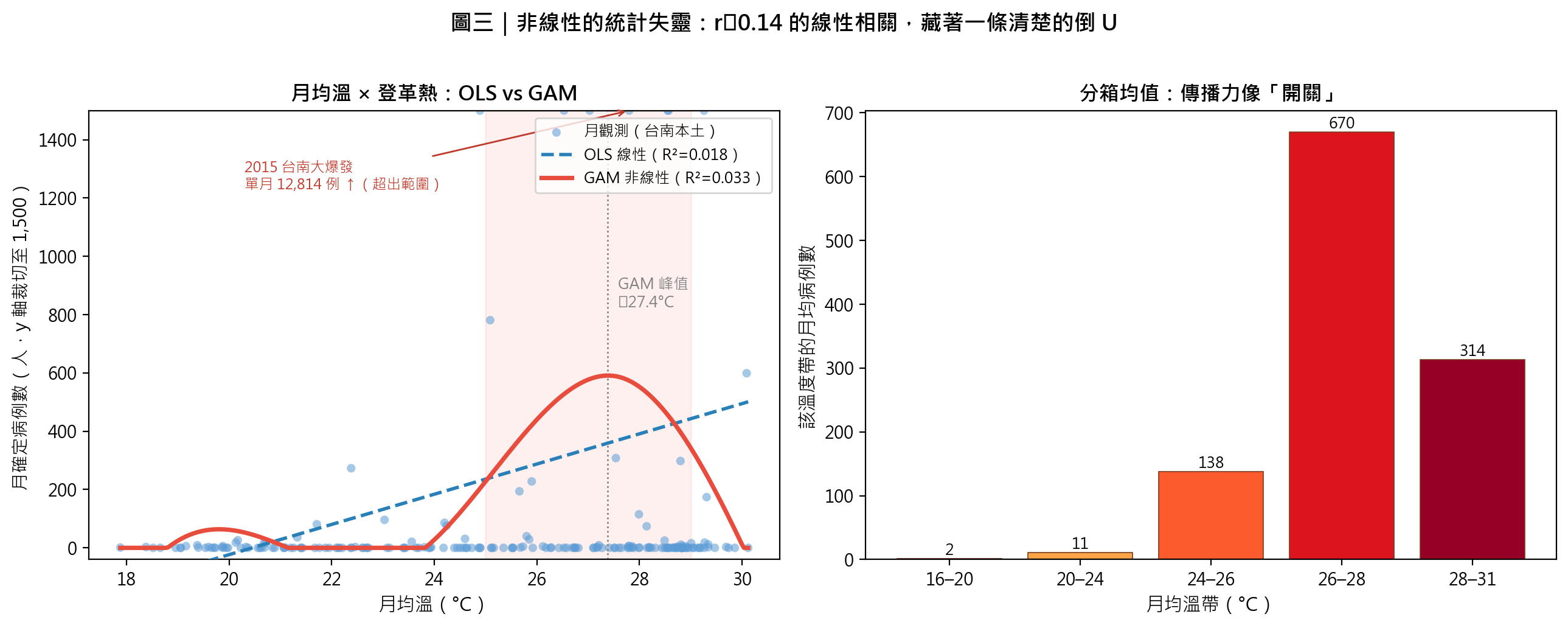
| 35–50 分 | 先跑 OLS | 看到 R²≈0.02、Pearson r≈0.14。提問:「電腦說溫度幾乎不影響疫情。你相信嗎?」 | 第 3 節 |
| 50–65 分 | 再跑 GAM | 同一份資料,GAM 畫出清楚的倒 U(峰值 ≈27.4°C);分箱均值 2→11→138→670→314。震撼時刻 | 第 4、5 節 |
| 65–80 分 | 解讀雙圖 | 左圖(散點+兩條擬合線)→ 右圖(分箱長條)。「線性的眼睛」看不見駝峰 | 第 6 節 |
| 80–90 分 | 收束與誠實 | 強調:即使 GAM 的 R² 也只有 0.03——氣溫是重要但非唯一因素。預告模組四:「換你親手把崩潰畫出來」 | 第 8 節 |
四、關鍵統計概念之淺白解釋
4.1 什麼是 GAM(廣義加成模型)?
- 直覺:OLS 強迫你用「一條直線」描述關係;GAM 讓資料自己決定曲線的彎法——它在每一小段溫度區間用平滑的樣條(spline)接合,最後拼成一條「會轉彎的線」。
- 與多項式迴歸的差別:多項式是「全域硬塞一個公式」;GAM 是「局部彈性、整體平滑」,比較不會被單一極端值拉歪。
- 教學比喻:OLS 像一把直尺,你只能畫直線;GAM 像一條可彎的雲尺(French curve),資料的形狀到哪,線就跟到哪。
4.2 相關係數的盲點:r ≈ 0 的兩種完全不同意思
- Pearson r 衡量的是「線性」關聯。
- 一個完美的倒 U(例如 y = −(x−5)²)算出來的 Pearson r 接近 0——但 x 與 y 顯然密切相關。
- 所以 r ≈ 0 有兩種互斥的可能:(1) 真的沒關係;(2) 有關係,但不是直線。只看 r 而不看散點圖,你永遠分不出是哪一種。
- 本模組的真實數據正是第 (2) 種:r=0.135、OLS R²=0.018,幾乎為零;但分箱與 GAM 都顯示一條清楚的駝峰。
4.3 什麼是「閾值反應」與「最適溫度」?
- 太冷(< 約 18–20°C):病媒蚊發育與病毒複製近乎停滯 → 傳播力 ≈ 0(資料中 16–20°C 月均僅 1.6 例)。
- 最適帶(約 26–29°C):傳播力最大(資料中 26–28°C 月均高達 670 例)。
- 過熱(> 約 30°C):蚊蟲壽命縮短、病毒複製受抑,傳播力反而下降(資料中 28–31°C 回落至 314 例)。
- 這條「先升後降」的曲線,與 Mordecai 等人(2017)以機制模型推得的「埃及斑蚊傳播最適溫度約 29°C」高度一致——我們用台南的真實病例,從觀測端重現了實驗室端的結論。
五、教學關鍵時刻:那條「電腦看不見的駝峰」
這是整堂課的高潮。建議教師預留 10–15 分鐘現場演示,並刻意製造「反轉」:
- 先讓電腦說謊。執行 OLS,把
R² = 0.018、Pearson r = 0.135投影到大螢幕。問全班:「如果你是只會跑迴歸、不畫圖的研究助理,你會在報告裡寫什麼?」——多數學生會說「溫度與登革熱幾乎無關」。 - 再讓資料說話。執行分箱均值,把
2 → 11 → 138 → 670 → 314這串數字念出來。全班會立刻發現:明明差超過 300 倍,怎麼可能「無關」? - 點破機制。畫出 GAM 曲線。解釋:OLS 之所以失明,是因為它只會問「整體而言,溫度越高病例越多嗎?」而倒 U 的左半(升)與右半(降)斜率正負相反,在線性模型裡相互抵消,於是 OLS 得到一條近乎水平的線,回報「無關」。
教學啟發(板書三句)
「相關係數低,不代表沒有關係,可能只代表關係不是直線。」
「先畫散點圖,再算統計量——這是資料工作者的第一條紀律。」
「模型是一副眼鏡。戴錯眼鏡,再清楚的東西你也看不見。」
這正呼應 Van Audenhove(2020)所稱「批判資料素養」:資料與模型都不是中立的,它們各自決定了「你被允許看見什麼形狀」。
六、常見學生提問與建議回應
既然 GAM 比較準,為什麼大家還在用 OLS?
OLS 簡單、可解釋、在「關係真的接近線性」時非常好用,而且它的係數有清楚的因果語意(「每升 1°C,平均多 X 例」)。
GAM 彈性大但較難用一個數字總結,也較容易過度貼合雜訊。重點不是「GAM 永遠比較好」,而是「先看形狀,再選工具」。
為什麼連 GAM 的 R² 也只有 0.03?這樣還能下結論嗎?
問得非常好,這是本模組最誠實的部分。登革熱爆發是多因子事件:降雨與積水容器、人口移動、前一年的群體免疫、孳生源清除、輸入病例的「引信」效應……氣溫只是其中之一。
我們的結論不是「氣溫決定疫情」,而是「氣溫與傳播的關係是非線性的,而這個非線性連微弱的線性訊號都會被 OLS 抹平」。
誠實表述(「重要但非唯一」)比聳動表述(「氣候害死多少人」)更有教育價值。
同月的氣溫和病例對比,會不會有「時間差」問題?
會,而且很重要。台灣登革熱高峰在秋季(9–11 月),但氣溫高峰在 7 月。「病媒蚊孳生 → 叮咬 → 潛伏 → 發病」需要數週。
進階練習:把氣溫
shift(1) 或 shift(2) 個月再比對,整體相關會明顯增強(OLS R² 從 0.02 升到約 0.15)。這是「落後效應」的絕佳教材。
這跟氣候變遷有什麼關係?
直接關係是:當台灣的「最適傳播溫度帶」(約 26–29°C)涵蓋的月份隨暖化而變多、變長、往北擴,登革熱的「可傳播窗口」就會拉長、地理範圍北移。
模組三教的非線性思維,正是理解「為什麼暖化幾度,疫情風險可能跳一階」的關鍵。
七、評量建議
7.1 形成性評量(課中)
請學生在右圖(分箱長條)上標出「開關打開」的那一個溫度帶,並用一句話解釋:「為什麼 24°C 以下幾乎沒有病例,26–28°C 卻暴增到 670 例?」
7.2 總結性評量(課後)
三擇一繳交 800–1,000 字短文:
- 統計素養題:自己造一組「完美倒 U」的假資料(例如 21 個點,y = −(x−5)²),計算它的 Pearson r 與 OLS R²。說明為什麼會得到接近 0 的值,並用這個例子向朋友解釋「r=0 的兩種意思」。
- 落後效應題:修改程式,將氣溫
shift(1)、shift(2)、shift(3)個月後分別與病例比對,列出三者的 OLS R²。解釋為何「落後 1–2 個月」會讓相關增強,並連結登革熱的傳播時間鏈。 - 跨模組整合題:把模組一(漸進剪刀)、模組二(結構斷層)、模組三(非線性閾值)三種統計形狀並列。各舉一個「你生活中可能因為用錯模型而誤判」的例子(如:考試成績、體重、社群追蹤數、投資報酬),說明若用錯形狀會得到什麼錯誤結論。
八、延伸閱讀
- Mordecai, E. A., et al. (2017). Detecting the impact of temperature on transmission of Zika, dengue, and chikungunya using mechanistic models. PLoS Neglected Tropical Diseases, 11(4), e0005568.
- Naish, S., Dale, P., Mackenzie, J. S., McBride, J., Mengersen, K., & Tong, S. (2014). Climate change and dengue: a critical and systematic review of quantitative modelling approaches. BMC Infectious Diseases, 14, 167.
- Hastie, T. J., & Tibshirani, R. J. (1990). Generalized Additive Models. Chapman & Hall/CRC.
- Anscombe, F. J. (1973). Graphs in statistical analysis. The American Statistician, 27(1), 17–21.(「先畫圖再算統計量」的經典)
- 衛生福利部疾病管制署(2016)。2015 年國內登革熱疫情回顧。疾管署統計資料。
- Van Audenhove, L., Van den Broeck, W., & Mariën, I. (2020). Data literacy and education. In The Routledge Handbook of Critical Data Studies.
教學者自我提醒:模組三是全課程的「方法論良心」。當學生離開教室時, 如果他學會了一句話「先讓我看看散點圖」,這個模組就成功了。