一、課堂前置準備
1.1 環境
- 建議平台:Google Colab(免安裝,瀏覽器即可)
- 備援平台:本地 Anaconda / JupyterLab
1.2 Colab 首次執行指令
!apt-get install -y fonts-noto-cjk -q執行後需重啟執行階段一次(Runtime → Restart),中文字型方能生效。
1.3 資料來源說明(重要背景)
本程式原先設計採用 Aono 教授(大阪公立大學)自官方網站釋出的 KyotoFullFlower7.xls。
然而,青野靖之教授於 2025 年 8 月辭世,其大學網頁於 2026 年 1 月起失效。
現程式改用兩個穩定鏡像依序嘗試:
- Our World in Data 官方 CSV(涵蓋最新年份)
- GitHub 鏡像
Ryo-N7/sakura_bloom(歷史穩定版本,止於 2015 年)
教學建議:在講授本模組前,不妨先以 1–2 分鐘向學生說明 Aono 教授的故事—— 他自學古日文以解讀《日本紀略》《御堂關白記》等平安朝文獻,親手建構了這份跨越十二個世紀的物候紀錄; 他辭世後,日本的一位研究者已接手延續此一記錄工作(見 Baraniuk, 2026, The Guardian)。 這段「資料的人類學」能深化學生對「資料並非自然存在、而是有人願意花一生去維護」的體認, 這正呼應 Van Audenhove(2021)所稱之「批判資料素養」——資料永遠有其生產條件與權力脈絡。
二、課堂節奏建議(90 分鐘版)
| 時段 | 內容 | 教學重點 | 對應程式 |
|---|---|---|---|
| 0–10 分 | 情境導入 | 播放京都花見影像、《古今和歌集》櫻花歌誦讀,建立文化共鳴 | — |
| 10–25 分 | 資料是什麼? | 讓學生先看 Aono 的史料來源(貴族日記、寺社紀錄)。強調「資料不是天上掉下來的」 | 第 1、2 節 |
| 25–40 分 | 跑一次程式 | 由教師示範執行 main(),讓學生觀察終端機輸出的數字 | 第 10 節 |
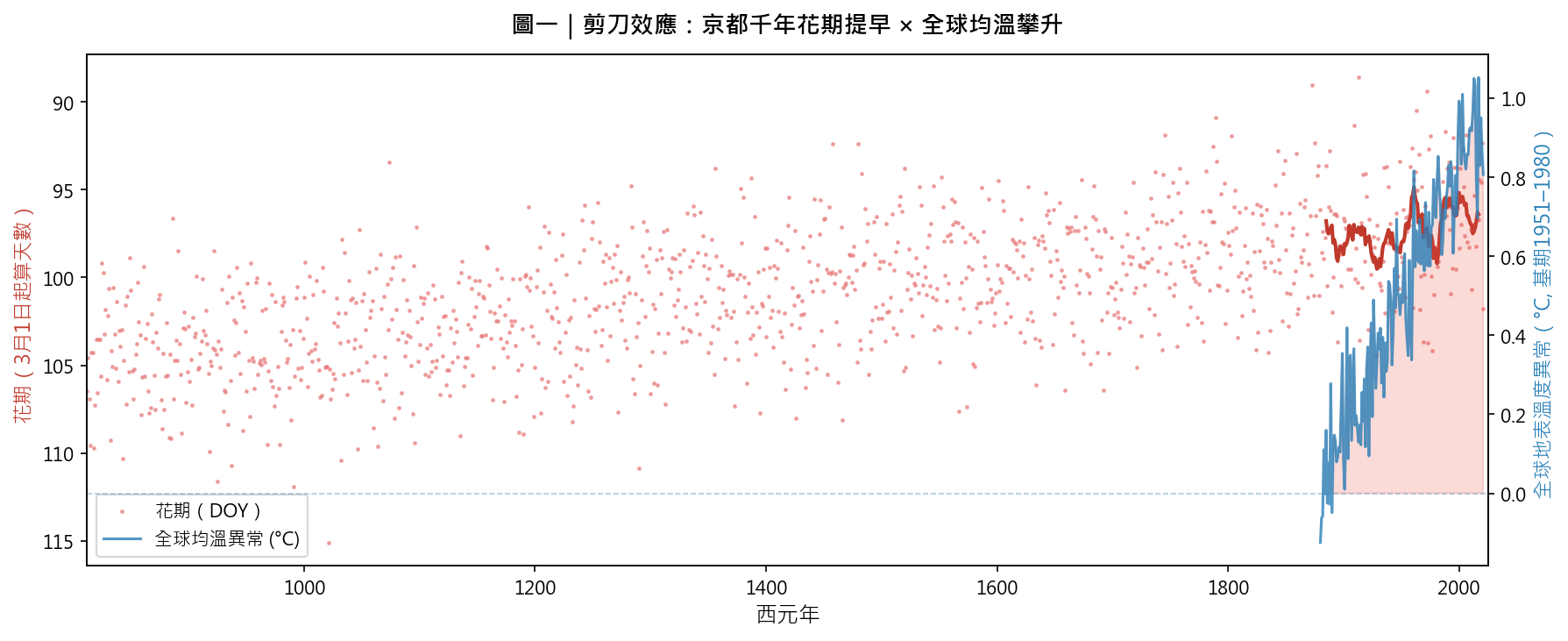
| 40–55 分 | 解讀剪刀效應圖 | 引導學生指出:紅線在哪裡開始「脫離」紅色零軸?粉線在哪個世紀開始「崩落」? | 第 7 節輸出圖 |
| 55–70 分 | 統計語言翻譯 | 把「β = −6.5 天/°C」「R² = 0.61」翻譯成日常語言。避免把 R² 說成「模型準確度」 | 第 4、5 節 |
| 70–85 分 | 分組討論 | 小組選一題(見程式第 11 節的五題),10 分鐘討論 + 各組 2 分鐘分享 | 第 11 節 |
| 85–90 分 | 收尾 | 連結下一模組:「如果千年的花期會錯亂,六百年的葡萄採收日又如何?」 | → 模組二 |
三、關鍵統計概念之淺白解釋
3.1 什麼是「年積日」(DOY)?
- 1 月 1 日 = 1,12 月 31 日 = 365(平年)。
- 為什麼要用 DOY 而不是「4 月 3 日」這種日期?因為跨越千年的曆法改動過多次(日本明治五年曾從舊曆切換到格里曆)。DOY 讓所有年份站在同一個數線上。
3.2 什麼是「氣溫異常值」(anomaly)?
- 定義:某年的氣溫減去 1951–1980 年的平均值。
- 為什麼不用絕對溫度:不同測站、不同高度、不同遮蔽條件的絕對溫度差異很大;但偏離基期的幅度在全球各地相對一致,因此適合做全球平均。
- 教學警語:若學生問「那 2024 年的 +1.1°C 是哪個地方的 +1.1°C?」——這是全球的平均,不代表台北、東京、倫敦都各升 1.1°C。事實上,北極升溫是全球平均的 3–4 倍。
3.3 什麼是 R² = 0.61?
- 正確說法:「氣溫異常值可解釋櫻花滿開日 61% 的年際變異。」
- 錯誤說法:「這個模型的準確度是 61%。」(R² 不是準確度。)
- 教學隱喻:想像一張有 100 粒散點的圖,61 粒排成一直線,剩下 39 粒散在旁邊——那 39 粒是「別的原因」,可能是 El Niño、局部天氣、或個別櫻花樹的品系差異。
3.4 Pearson vs. Spearman
- Pearson:測「線性相關」。
- Spearman:測「單調關係」(不必是直線,只要一路上升或下降)。
- 教學提示:若 |Spearman| > |Pearson|,代表關係可能不是直線。在氣候資料上,若兩者差距很小,代表線性假設還算合理,用 OLS 迴歸不會太離譜。
四、常見學生提問與建議回應
老師,這代表以後京都會沒有櫻花嗎?
不會。櫻花樹本身不會消失,但它的「花期時間點」會持續往前推。極端情境下(持續升溫 4°C 以上),有些地區可能因冬季低溫不足(chilling hours 不夠)而不開花,這在美國喬治亞州的桃花產業已經發生。
為什麼用 NASA 的資料,不用中央氣象署?
京都櫻花是「在地現象」,氣溫卻需要「全球信號」。如果用日本局部氣溫,會受到日本都市熱島效應污染,反而高估相關性。全球平均可濾掉在地雜訊,抓住的是「全球升溫驅動的在地反應」。
Aono 怎麼知道平安時代的花期?他又沒在那裡。
非常好的問題——這就是資料批判的精髓。Aono 用的是歷史文獻:貴族日記(如《御堂關白記》)、寺社紀錄、和歌集中的花見詩句。每筆紀錄都有「可信度標籤」(DataType 欄位),教師可示範篩選高可信度子集重跑迴歸,結果仍然顯著——這就是「穩健性檢定」(robustness check)的實際操作。
那我們現在該怎麼辦?
此模組的目的不在行動方案,而在建立「看見—理解—感受」的認識論基礎。行動方案留給模組五(行為改變)。此時若學生問,可回應:「我們先讓自己成為一個『看得見氣候變遷』的人,再來談『做什麼』。」——此即 Ojala(2012)賦能式教育的順序。
五、評量建議
5.1 形成性評量(課中)
每組在剪刀效應圖上標出兩個年份:一個是「氣溫與花期同步變化」的年份、一個是「兩者不同步」的年份。並解釋為何會不同步(答:自然變異 / 單年雜訊)。
5.2 總結性評量(課後)
請學生自選下列一題繳交 800 字短文:
- 資料批判題:篩選 1800 年以後的資料重跑迴歸(教師提供程式碼片段),說明 β 值變化的原因。
- 文化詮釋題:從《萬葉集》或《源氏物語》中找一段與櫻花時序相關的文字,討論其與本模組資料所呈現之現象的異同。
- 政策推論題:若京都市府委託你規劃 2030 年的花見祭活動,你會如何依照本模組的推論結果建議活動日期?有何風險?
六、延伸閱讀(教師自修)
- Aono, Y., & Kazui, K. (2008). Phenological data series of cherry tree flowering in Kyoto, Japan, and its application to reconstruction of springtime temperatures since the 9th century. International Journal of Climatology, 28(7), 905–914.
- Cunsolo, A., & Ellis, N. R. (2018). Ecological grief as a mental health response to climate change-related loss. Nature Climate Change, 8(4), 275–281.
- Primack, R. B., Higuchi, H., & Miller-Rushing, A. J. (2009). The impact of climate change on cherry trees and other species in Japan. Biological Conservation, 142(9), 1943–1949.
- Ojala, M. (2012). Hope and climate change: The importance of hope for environmental engagement among young people. Environmental Education Research, 18(5), 625–642.
教學者自我提醒:本模組的核心不是教 Python,而是教「如何在一張雙軸圖前保持清醒」。 若整堂課下來,學生只記得「β = −6.5」卻忘了為什麼這個數字令人心疼,那就是本末倒置。